Technical Overview > Architecture
Components of the CHT Ecosystem
Setting up Grafana and Prometheus with the CHT
Medic maintains CHT Watchdog which is an opinionated configuration of Prometheus (including json_exporter) and Grafana which can easily be deployed using Docker. It is supported on CHT 3.12 and later, including CHT 4.x and 5.x. By using this solution a CHT deployment can easily get longitudinal monitoring and push alerts using Email, Slack or other mechanisms. All tools are open source and have no licensing fees.
The solution provides both an overview dashboard as well as a detail dashboard. Here is a portion of the overview dashboard:
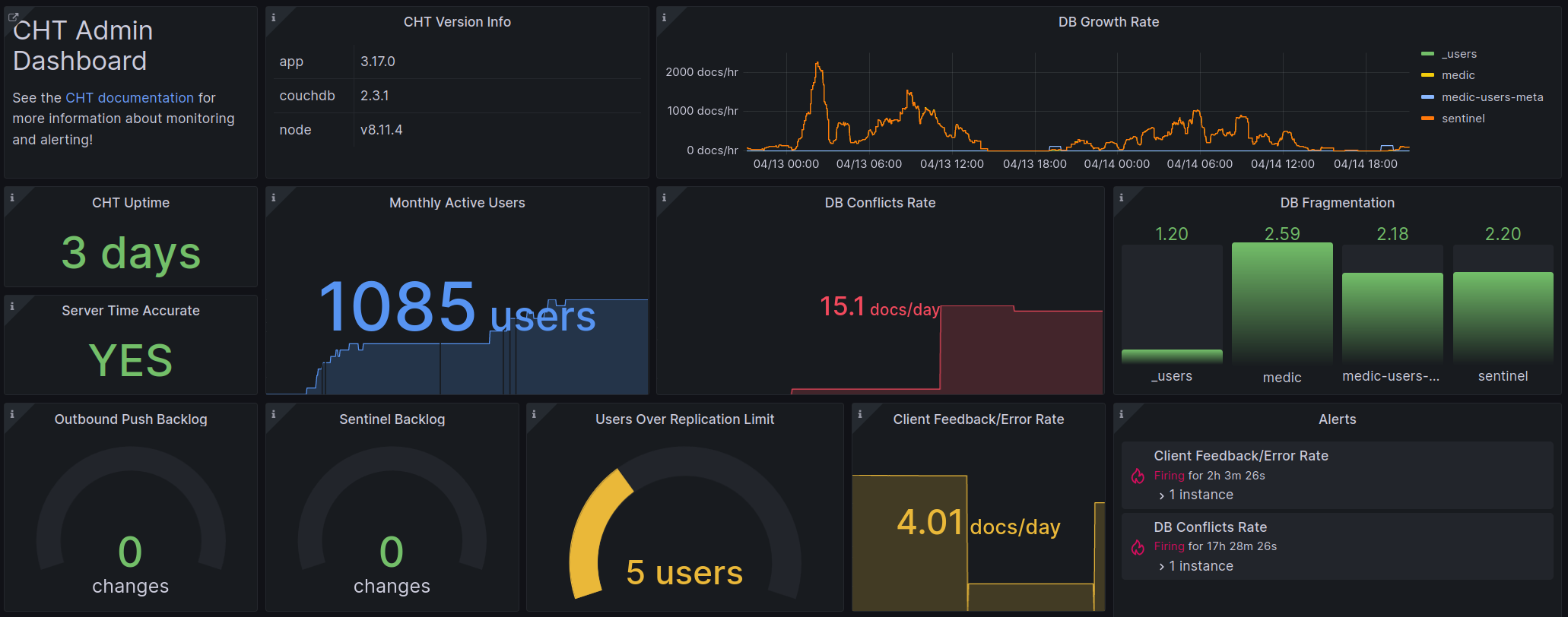
Screenshot of Grafana Dashboard showing data from Prometheus
Prometheus supports four metric types: Counter, Gauge, Histogram, and Summary. Currently, the CHT only provides Counter and Gauge type metrics. When building panels for Grafana dashboards, Prometheus Functions can be used to manipulate the metric data. Refer to the Grafana Documentation for best practices on building dashboards.
Warning
Always run Watchdog on a different server than the CHT Core. This ensures Watchdog doesn’t fail if the CHT Core server fails and alerts will always be sent. The instructions assume you’re connecting over the public Internet and no special VPN or routing is required.
These instructions have been tested against Ubuntu, but should work against any OS that meets the prerequisites. They follow a happy path assuming you need to only set a secure password and specify the URL(s) to monitor:
Run the following commands to clone this repository, initialize your .env file, create a secure password and create your data directories:
cd ~
git clone https://github.com/medic/cht-watchdog.git
cd cht-watchdog
cp cht-instances.example.yml cht-instances.yml
cp grafana/grafana.example.ini grafana/grafana.ini
mkdir -p grafana/data && mkdir -p prometheus/data
sudo apt install -y wamerican # ensures /usr/share/dict/words is present for shuf call below
cp .env.example .env
password=$(shuf -n7 /usr/share/dict/words --random-source=/dev/random | tr '\n' '-' | tr -d "'" | cut -d'-' -f1,2,3,4,5,6,7)
sed -i -e "s/password/$password/g" .env
echo;echo "Initial project structure created! To log into Grafana in the browser:";echo
echo " username: medic"
echo " password: ${password}";echoIf you’re using docker-compose v2.x, it doesn’t support relative paths and you’ll have to edit your .env file to update paths to absolute path.
Note that in step 4 below you’ll need the username and password which is printed after you run the above command.
Edit the cht-instances.yml file to have the URLs of your CHT instances. You may include as many URLs of CHT instances as you like.
Here is an example:
- targets:
- https://subsub.sub.example.com
- https://cht.domain.com
- https://website.orgRun the following command to deploy the stack:
cd ~/cht-watchdog
docker compose up -dGrafana is available at http://localhost:3000. See the output from step 1 for your username and password.
If you would like to do more customizing of your deployment, see “Additional Configuration”.
Before upgrading, you should back up both your current configuration settings as well as your Prometheus/Grafana data directories.
To upgrade these dependencies, update the version numbers set in your .env file (or leave them set to latest). Then run the following commands:
docker compose pull
docker compose up -dWhen you see a new version in the GitHub repository, first review the release notes and upgrade instructions. Then, run the following commands to deploy the new configuration (be sure to replace TAG with the tag name associated with the release (e.g. 1.1.0)):
cd ~/cht-watchdog
git fetch
git -c advice.detachedHead=false checkout TAG
docker compose pull
docker compose down
docker compose up -d --remove-orphansWhen making any changes to your CHT Watchdog configuration (e.g. adding/removing instances from the cht-instances.yml file) make sure to restart all services to pick up the changes:
cd ~/cht-watchdog
docker compose down
docker compose up -dWith the release of 1.1.0, Watchdog now supports easily ingesting CHT Sync data read in from a Postgres database (supports Postgres >= 9.x).
Copy the example config file, so you can add the correct contents in them:
cd ~/cht-watchdog
cp exporters/postgres/sql_servers_example.yml exporters/postgres/sql_servers.ymlEdit sql_servers.yml you just created and add your target postgres connection URL. For example, if your postgres server was db.example.com, your user was db_user and your password was db_password, the config would be:
- targets:
"db-example-com": 'postgres://db_user:db_password@db.example.com:5432/cht?sslmode=disable' # //NOSONAR - password is safe to commitYou may add as many targets as you would like here - one for each CHT Core instance in your cht-instances.yml file. Be sure to match the key (db-example-com in this example) to the exact value defined in your cht-instances.yml file while ensuring the entry is unique.
Start your instance up, being sure to include both the existing docker-compose.yml and the docker-compose.postgres-exporter.yml file:
cd ~/cht-watchdog
docker compose -f docker-compose.yml -f exporters/postgres/compose.yml up -dWarning
Always run this longer version of the docker compose command which specifies both compose files for all future upgrades.
While not the default setup, and not what most deployments need, you may want to set up a way to monitor CHT Sync data without sharing any Postgres credentials. Instead of sharing credentials, you expose an HTTP endpoint that requires no login or password. Of course, similar to CHT Core’s Monitoring API, this endpoint should be configured to not share sensitive information (since it will be publicly accessible).
This section has two steps. The first is to expose the password-less metrics endpoint and the second is to scrape it with Prometheus. Here’s documentation on how to set up a Kubernetes or Docker endpoint for CHT Sync.
metrics_exporter value in your values.yaml file and make sure enabled is set to true.service.type to LoadBalancer or NodePort in your values.yaml file.Continue on to set up the scrape on Watchdog.
These commands set up a SQL Exporter and should be run on your Postgres server:
git clone git@github.com:medic/cht-watchdog.git and cd into cht-watchdogexporters/postgres/sql_servers_example.yml to exporters/postgres/sql_servers.ymlexporters/postgres/sql_servers.yml file to have the correct credentials for your server. You need to update the USERNAME and PASSWORD. You may need to update the IP address and port also, but likely the default values are correct..env.example to .env.env file, edit SQL_EXPORTER_IP to be the public IP of the Posgtres serverdocker compose --env-file .env -f exporters/postgres/compose.yml -f exporters/postgres/compose.stand-alone.yml up -dSQL_EXPORTER_IP was set to 10.220.249.15, then this would be: http://10.220.249.15:9399/metrics. The last line starting with up{job="db_targets"... should end in a 1 denoting the system is working. If it ends in 0 - check your docker logs for errors.Continue on to set up the scrape on Watchdog.
No matter which way you set up your SQL exporter, follow these steps to tell your Watchdog instance to scrape the new endpoint.
cp exporters/postgres/scrape.yml ./exporters/postgres/scrape-custom.ymlscrape-custom.yml so that it has the ip address of SQL_EXPORTER_IP from step 7 above. If that was 10.220.249.15, then you file would look like: scrape_configs:
- job_name: sql_exporter
static_configs:
- targets: ['10.220.249.15:9399']compose.scrape-only.yml compose file:docker compose --env-file .env -f exporters/postgres/compose.yml -f exporters/postgres/compose.scrape-only.yml up -d* The compose.stand-alone.yml and compose.scrape-only.yml compose files override some services. This is done so that no manual edits are needed to any compose files.
By default, historical monitoring data will be stored in Prometheus (PROMETHEUS_DATA directory) for 60 days (configurable by PROMETHEUS_RETENTION_TIME). A longer retention time can be configured to allow for longer-term analysis of the data. However, this will increase the size of the Prometheus data volume.
Alternatively, to limit the maximum storage used, set PROMETHEUS_RETENTION_SIZE to a value like 10GB or 500MB. This defaults to 0 which means no limit. When both time and size limits are configured, whichever threshold is reached first will trigger data removal.
See the Prometheus documentation for more information.
Local storage is not suitable for storing large amounts of monitoring data. If you intend to store multiple years worth of metrics, you should consider integrating Prometheus with a Remote Storage.
This configuration includes number of pre-provisioned alert rules. Additional alerting rules (and other contact points) can be set in the Grafana UI.
See both the Grafana high level alert Documentation and provisioning alerts in the UI for more information.
The provisioned alert rules shipped with CHT Watchdog are intended to be the generally applicable for most CHT deployments. However, not all the alert rules will necessarily be useful for everyone. If you would like to delete any of the provisioned alert rules, you can do so with the following steps:
In Grafana, navigate to “Alerting” and then “Alert Rules” and click the eye icon for the rule you want to delete. Copy the Rule UID which can be found on the right and is a 10 character value like mASYtCQ2j.
Create a delete-rules.yml file
cd ~/cht-watchdog
cp grafana/provisioning/alerting/delete-rules.example.yml grafana/provisioning/alerting/delete-rules.ymlUpdate your new delete-rules.yml file to include the Rule UID(s) of the alert rule(s) you want to delete
Restart Grafana
docker compose restart grafanaIf you ever want to re-enable the alert rules you deleted, you can simply remove the Rule UID(s) from the delete-rules.yml file and restart Grafana again.
The provisioned alert rules cannot be modified directly. Instead, you can copy the configuration of a provisioned alert into a new custom alert with the desired changes. Then, remove the provisioned alert.
Grafana supports sending alerts via a number of different methods. Two likely options are Email and Slack.
To support sending email alerts from Grafana, you must update the smtp section of your grafana/grafana.ini file with your SMTP server configuration. Then, in the web interface, add the desired recipient email addresses in the grafana-default-email contact point settings.
Slack alerts can be configured within the Grafana web GUI for the specific rules you would like to alert on.
See the example .env file for a list of all environment variables that can be set.
Components of the CHT Ecosystem
Monitoring and alerting system using Grafana and Prometheus